
Recognition vs. Reference: Why Generative AI Doesn't Quite See the Same Object Twice
Modern image models can produce a believable picture of almost anything. But producing a watch is not the same as producing your watch. A note on the conceptual gap that genuine 3D modeling has to close.
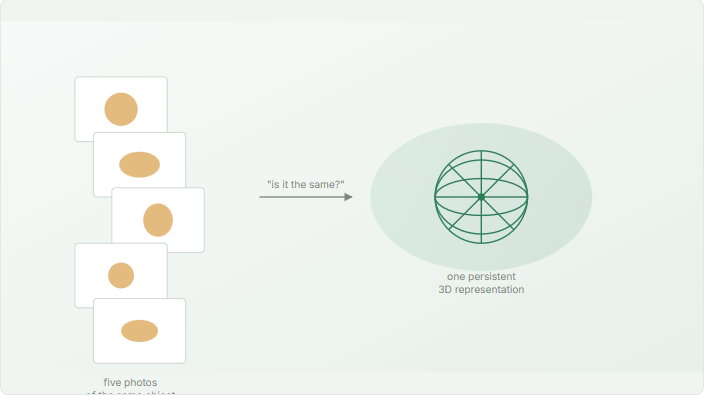
A watchmaker keeps a small lacquered tray of tools beside the bench. The screwdrivers have been worn into shapes that match a particular hand. Now imagine asking a modern image model to render that same hand using one of those same screwdrivers in a new scene. The model will produce a hand, and a screwdriver, and it will look convincing. What it will not do is produce that hand with that screwdriver. This small gap, between knowing what a thing looks like and knowing which thing it is, is what this note is about.
Over the past two years, the conversation around generative AI has been dominated by what these models can now do. Photorealistic portraits in seconds. A coffee mug placed convincingly into a sunlit kitchen. A product rendered in five styles before lunch. The fluency is real, and it is genuinely useful. But anyone who has tried to use these tools for a specific, repeating object — a particular machine part, a personal heirloom, an actor's body across scenes, a piece of inventory that must look the same in every catalog shot — has run into the same wall. The model can describe the kind of thing very well. It struggles to refer to the individual instance. This is not a temporary engineering limitation that will be fixed in the next release. It points at a deeper distinction in how today's image models are built, and at why genuine 3D representation — the kind we build at Green Box AI — is becoming less of a luxury and more of a structural requirement. Let us walk through the gap carefully. When practitioners say a model "preserves identity," they are usually conflating four very different things. Disentangling them clarifies why some demos look magical and other ordinary tasks remain awkward. Most public conversation about "identity preservation" is really about L2 or L3. The face case is solved because faces are abundant, structurally constrained, and surrounded by industrial-grade datasets. Personalization for arbitrary objects is harder but workable for short-horizon use. What remains genuinely difficult is L4 — and L4 is precisely what production work tends to need. The asymmetry between L2 and L3 is not architectural; it is statistical. Three reasons. Data scale. Tens of millions of labeled face images exist in publicly trained datasets. Comparable corpora for a worn boot, a particular bracelet, a specific anatomical part, or a unique industrial fitting do not. A model can only learn what its training data has seen at sufficient volume. Geometric prior. All human faces fit inside a parametric space of roughly a few hundred dimensions. Manufactured objects do not have such a tight prior, and personal possessions diverge further with age and wear. There is no equivalent of a face mesh for "this particular brass valve in its current condition." Relative size in the frame. In a portrait, a face occupies twenty to fifty percent of the image. A small bracket, a tattoo, a unique mole, or a hand in a full-body composition might occupy less than five percent of pixels — and the model's identity-encoding capacity correspondingly collapses. Recent work calls this identity feature leakage: the identifying signal gets absorbed into the surrounding clothing or scenery instead of staying on the part that defines the object. These three facts together explain why a generative system can place a celebrity at the Eiffel Tower convincingly, yet struggle to place your golf club into your backyard. The architecture is not unequal to the task. The data and the priors are. Beneath the data question sits a more fundamental one. Image diffusion models, including the strongest ones available in 2026, learn a probability distribution over two-dimensional pixels. They sample plausible images. They do not, by construction, build an internal model of the three-dimensional world that produced those images. They are, in the language of computer graphics, image-based rather than geometry-based. This is a design choice, not a defect. It is what makes the models fast, flexible, and capable of beautiful style transfer. But it also means that when you give a 2D model five photographs of an object and ask it to imagine the sixth, the model is interpolating in a high-dimensional manifold of views — not reasoning about the object that produced them. If the new view falls inside the cloud of plausible images the model has seen during training, the result is convincing. If the new view is far from anything in the cloud — a steep angle, an unusual occlusion, a lighting condition the training data underrepresented — the model often produces something that looks correct from far away but is geometrically incoherent up close. By contrast, a genuine 3D representation — a mesh, a neural radiance field, a Gaussian splat — is a function of spatial coordinates. It does not store "views of the object." It stores the object. Asked for a new viewpoint, it does not sample from a distribution; it queries a geometry. Asked to relight, it does not invent shading; it computes it from surface normals. This is the difference between describing how something looked the last time you saw it and knowing where it is on the shelf right now. Philosophers of language have an old distinction that is unexpectedly useful here. They separate describing a kind of thing from referring to a particular thing. When you say "the chair in the kitchen," you are pointing at a specific physical object; when you say "a kitchen chair," you are describing a category that contains many instances. The two operations look similar in language but are mechanically different in the brain — and different in software. Generative image models, almost without exception, operate on the descriptive side. They have learned a rich vocabulary of categories: woods, fabrics, postures, machine parts, animal species, lighting moods. Given a prompt, they assemble a plausible member of the described category. That is recognition done very well. What they cannot do natively is refer — to point at a single individual object and produce that one reliably across many contexts. A LoRA or a personalization adapter approximates reference by carving out a small region of the latent space and labeling it "this one." It works, often beautifully, within the conditions the training data covered. It does not, however, give the model a sense that there exists a single physical object in the world that all these images were photographs of. This is the gap. And once you see it, you start to notice it everywhere: in an e-commerce shoot where the same handbag appears slightly different in each catalog image; in a training video where a tool changes proportion between cuts; in a virtual try-on that almost matches the customer's body but not quite; in an architectural visualization where the same fixture varies in two viewing angles. The category survives. The individual drifts. The practical implications are not abstract. They show up across the industries our team works with daily. E-commerce. A retailer needs every product to look identical across every angle, every lifestyle scene, every device size. Generated views of a product, no matter how convincing, fail at scale precisely when the individual instance is what matters. The customer is buying that exact watch, not a credible-looking watch. AR product placement. Placing furniture in a customer's living room is not a styling problem; it is a measurement problem. If the chair in the AR scene is two centimeters off in any dimension, the customer either trips on it or returns it. Geometric reference is non-negotiable. Training and simulation. A safety module showing a technician how to handle a specific drill needs the drill to behave like the drill in the workshop. If the chuck threads drift between frames, the trainee learns the wrong motion. Cultural heritage and conservation. A digitized figurine is a record. It must remain the same record across decades, across museum systems, across reproductions. A descriptive likeness is not a record. Medical and anatomical applications. A patient's anatomy is not a category. It is a particular geometry that has consequences in surgical planning, prosthetic fitting, and rehabilitation modeling. The cost of confusing recognition for reference here is not aesthetic. In each of these cases, the answer is not a better generative model in the 2D-distributional sense. The answer is a representation that genuinely refers — that holds, in its data structure, the actual three-dimensional shape of the actual object. That is the work. Our patent (WIPO WO2020217082) is built around exactly this conviction: that the right starting point for a faithful digital twin is geometry, not appearance. The GreenDot Engine treats every input photo as evidence in a geometric experiment. The OmniModel 3D pipeline democratizes that experiment to anyone with a phone. CloudCraft 3D Studio, FlexModel, and ImmersiView wrap the geometric core in production-ready services for industries where reference, not recognition, is the deliverable. This is not a critique of generative AI. We use generative methods inside our own pipeline, especially for texture synthesis and the harder cases of view completion. The point is that generative and geometric tools answer different questions, and a mature pipeline keeps each in its proper role. Generative tools answer "what kind of thing might this be." Geometric tools answer "what specifically is this." For most of the work our customers bring us, only the second answer is useful. What is changing in 2026, and what gives us cautious optimism, is that the two stacks are starting to interoperate cleanly. Meta's release of SAM 3D Body in late 2025, the maturation of Gaussian Splatting reconstruction from sparse inputs, the arrival of part-aware 3D foundation models, and our own work on geometry-preserving reconstruction from casual phone captures — all of these point at the same conclusion. The future of believable digital twins is not generative on its own. It is geometry, supported by generative methods where appropriate, anchored in a representation that knows which object it is looking at. The same object, photographed five times from five angles in five lightings, is one object. The task is to build software that knows this — not because we told it the right words, but because the representation itself is structured to insist on it. That is the work. It is the work we set out to do at Green Box AI six years ago, and it is the work that gets more relevant, not less, the better the rest of the field gets at producing beautiful but transient images.Four meanings of "identity," only three of which are easy
Level
What is preserved
State of the art (May 2026)
L1 Appearance similarity
A style, a texture, a palette — but not any specific entity.
Long solved. Anything that resembles the input loosely will pass.
L2 Face identity
A compact identity vector for a human face.
Mostly solved. Models like InstantID, PhotoMaker, and PuLID rebuild faces from a single photo with high fidelity.
L3 Subject-driven personalization
A specific object or person learned via fine-tuning or a reference embedding.
Partial. DreamBooth, LoRA, IP-Adapter, OmniGen2, and Flux Kontext all sit here. Works well at angles seen in the reference set; degrades elsewhere.
L4 Persistent 3D identity
A geometric representation of the specific object, renderable from any viewpoint under any lighting.
Open. This is the level genuine 3D modeling is built to provide.
Why faces work and almost everything else doesn't
The deeper layer: distribution versus structure
Recognition is not reference
Why this matters for the practical work in front of us
Closing the gap from the geometry side